Every few months, the frontier model leaderboard shifts again. Anthropic’s Claude Opus 4.7 and OpenAI’s GPT-5.4 are the latest pair of heavyweights competing for enterprise budgets — and the decision is no longer just about benchmark scores.
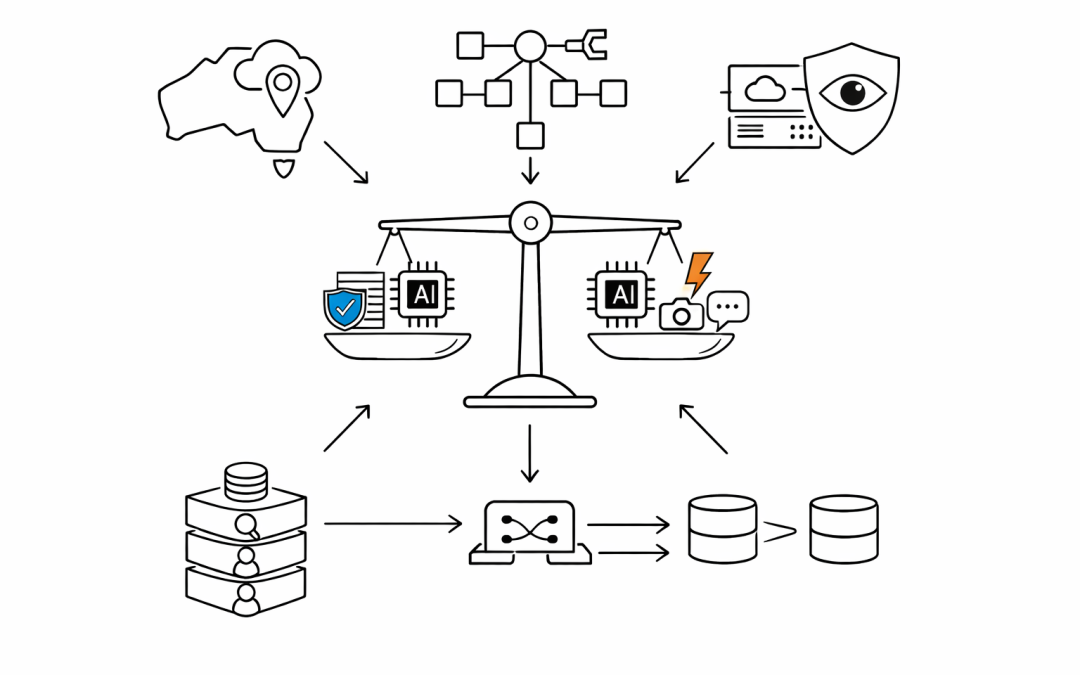
For Australian CIOs and IT directors, the real question isn’t “which model is smarter?” It’s “which model fits our risk appetite, data sovereignty requirements, cost model, and the workflows we’re trying to automate?”
The answer isn’t the same for every organisation. Here’s how our team is helping clients think through the choice.
The Short Version
Both models are genuinely excellent. Either can handle the vast majority of enterprise workloads — summarisation, coding assistance, document analysis, customer support, agentic workflows. The differentiators show up at the edges.
Claude Opus 4.7 tends to win on long-context reasoning, tool-use reliability, and safety posture. GPT-5.4 tends to win on raw speed, multi-modal breadth, and cost-per-token on the smaller variants.
But those are generalisations. The model that’s right for a specific organisation depends on four questions that have little to do with benchmarks.
Question 1: Where Does the Data Need to Live?
This is the first filter, and it eliminates more options than most executives realise.
Organisations bound by the Australian Privacy Principles, APRA CPS 234, or agencies following ACSC guidance often need data residency in Australian regions. Both Anthropic and OpenAI are now available through Australian-resident deployment paths — Claude via AWS Bedrock in ap-southeast-2 and GPT-5.4 via Azure OpenAI in Australia East — but the operational details differ.
Azure OpenAI offers the more mature Australian footprint, including regional failover and a longer track record of handling government and regulated workloads. Bedrock’s Claude deployment is catching up quickly but still has some features that only ship in US regions first.
For organisations in financial services, healthcare, or government, this often makes the choice for them before capability is even considered.
Question 2: What Are You Actually Building?
The second filter is workload shape.
For agentic workflows and tool use — systems that chain multiple actions, call APIs, and make decisions — Claude Opus 4.7 has a measurable edge. Its tool-calling accuracy and willingness to stop and ask for clarification tend to produce more predictable behaviour in production. This matters when an agent is processing invoices, triaging tickets, or interacting with internal systems where hallucinations have real consequences.
For high-volume, latency-sensitive workloads — real-time chat, code completion, document classification at scale — GPT-5.4 and its smaller siblings often win on throughput and cost. The GPT-5.4-mini tier in particular has become the default for organisations running millions of requests per day.
For long-document analysis — contracts, regulatory filings, technical documentation — Claude’s context handling remains best-in-class. Summarising a 300-page document with fewer hallucinations is a measurable productivity win.
For multi-modal work — image understanding, document OCR with layout awareness, voice — GPT-5.4 currently has the broader feature set.
Question 3: What’s Your Integration Surface?
The model is only half the story. The platform around it often determines the total cost of ownership.
Organisations already standardised on Microsoft 365, Azure, and Entra ID typically find GPT-5.4 via Azure OpenAI the path of least resistance. Identity, logging, network controls, Purview data protection, and Defender for Cloud all integrate natively. For a Microsoft-centric enterprise, switching to Claude means a second control plane.
Organisations running on AWS or with a heavier data engineering footprint often prefer Bedrock’s Claude deployment because it sits closer to where their data already lives.
Neither choice is wrong. But pretending the integration surface is free is where projects run into unexpected cost and complexity six months in.
Question 4: How Sensitive Are You to Safety and Brand Risk?
Both vendors invest heavily in safety, but their philosophies differ.
Anthropic’s Constitutional AI approach produces a model that tends to be more cautious — it refuses more often, explains its reasoning about refusals, and is generally less likely to produce content that creates brand risk. For customer-facing workloads, regulated industries, and government, this conservatism is usually a feature, not a bug.
OpenAI’s approach gives more flexibility to the developer, with more configurable safety controls. For internal tools where speed and capability matter more than guardrails, that flexibility is valuable.
Organisations with a low tolerance for brand risk — particularly in financial services, healthcare, and the public sector — often land on Claude for external-facing use cases even when GPT-5.4 wins on other dimensions.
The Hidden Cost Most Procurement Teams Miss
Token pricing is the wrong lens for comparing these models.
The real cost is the total cost of a workflow: model inference plus retrieval plus orchestration plus monitoring plus human review of edge cases. A cheaper model that fails more often on complex tasks is more expensive overall. A premium model that reliably handles 95% of cases without review can pay for itself in saved human hours.
Most organisations we work with underestimate this by an order of magnitude. The question isn’t “what does a million tokens cost?” It’s “what does it cost to complete one end-to-end task reliably, at scale, with appropriate governance?”
Don’t Pick One. Pick Both.
The most mature Australian organisations are no longer standardising on a single frontier model. They’re building abstraction layers — using frameworks like LangChain, Semantic Kernel, or custom routing — that let them send different workloads to different models based on fit.
High-volume classification runs on a smaller, cheaper model. Long-document analysis routes to Claude. Multi-modal tasks go to GPT-5.4. Agentic workflows use whichever model’s tool-use is more reliable for that specific task.
This multi-model posture also provides leverage on pricing and resilience when one vendor has an outage — which both have had in the last twelve months.
What to Do This Quarter
For organisations still on a single model or still debating the choice, three practical steps:
- Classify your workloads. List the AI use cases already in production or in pilot, and score each one against the four questions above. The answer will emerge from the data.
- Pilot the second model. Even if one vendor is clearly the primary choice, run a small pilot on the alternative. The cost is low and the learning is high.
- Build the abstraction now. Before the next model release — and there will be one — put a routing layer between the application code and the model APIs. It’s cheap insurance against lock-in.
The frontier will keep shifting. The organisations that win aren’t the ones that pick the right model today. They’re the ones that build the discipline to keep picking the right model every quarter.
If your organisation is navigating this decision and wants an independent perspective on model selection, architecture, and governance, our team works with Australian businesses every day on exactly this question. We’d be glad to help.
Discover more from CPI Consulting
Subscribe to get the latest posts sent to your email.