
In this post, “LLM Self-Attention Mechanism Explained”we’ll break down how self-attention works, why it’s important, and how to implement it with code examples.
Self-attention is one of the core components powering Large Language Models (LLMs) like GPT, BERT, and Transformer-based architectures. It allows a model to dynamically focus on different parts of an input sequence when processing each word or token, enabling better understanding of context, relationships, and meaning.
Table of contents
What is Self-Attention?
Self-attention computes the relevance of each token in a sequence to every other token. Instead of processing words in isolation, it assigns attention weights that determine how much one word should influence another’s representation.
For example, in the sentence:
“The cat sat on the mat.”
When processing the word “sat”, the model should give higher weight to “cat” and “mat” than to “the” because they provide more relevant context.
Why Self-Attention is Important in LLMs
Self-attention allows LLMs to capture long-range dependencies, unlike RNNs which struggle with distant word relationships. It processes input sequences in parallel, avoiding the slow sequential nature of older architectures, and adapts dynamically because weights change for each new input sequence. This flexibility makes self-attention the foundation of modern NLP breakthroughs.
The Self-Attention Computation
The computation involves three main vectors:
- Query (Q) – Represents what we are looking for.
- Key (K) – Represents the index of information.
- Value (V) – Holds the actual content to be retrieved.
Steps:
- Input embeddings are projected into Q, K, and V using learned weight matrices.
- Attention scores are computed by taking the dot product of Q and K.
- Scaling is applied to prevent large dot-product values from dominating the softmax.
- Softmax normalizes the scores into probabilities.
- A weighted sum of V is calculated based on these probabilities.
Example in PyTorch
import torch
import torch.nn.functional as F
# Example input: batch_size=1, sequence_length=4, embedding_dim=5
x = torch.randn(1, 4, 5)
# Weight matrices for Q, K, V
W_q = torch.randn(5, 5)
W_k = torch.randn(5, 5)
W_v = torch.randn(5, 5)
# Step 1: Compute Q, K, V
Q = x @ W_q
K = x @ W_k
V = x @ W_v
# Step 2: Compute attention scores
scores = Q @ K.transpose(-2, -1)
# Step 3: Scale
scale = Q.size(-1) ** 0.5
scores = scores / scale
# Step 4: Apply softmax
weights = F.softmax(scores, dim=-1)
# Step 5: Weighted sum of values
output = weights @ V
print("Attention Weights:\n", weights)
print("Output:\n", output)
A Simple Numerical Example
Let’s say we have a 3-word sequence with scalar embeddings:
- Input embeddings: [1, 2, 3]
- Q = K = V = same as input (for simplicity)
Step 1:
Compute scores:
QK^T = [[1*1, 1*2, 1*3],
[2*1, 2*2, 2*3],
[3*1, 3*2, 3*3]]
Step 2:
Scale and softmax to get attention weights.
Step 3:
Multiply weights by V to get the final output.
Self-Attention Diagram
Below is a conceptual diagram of the self-attention process:
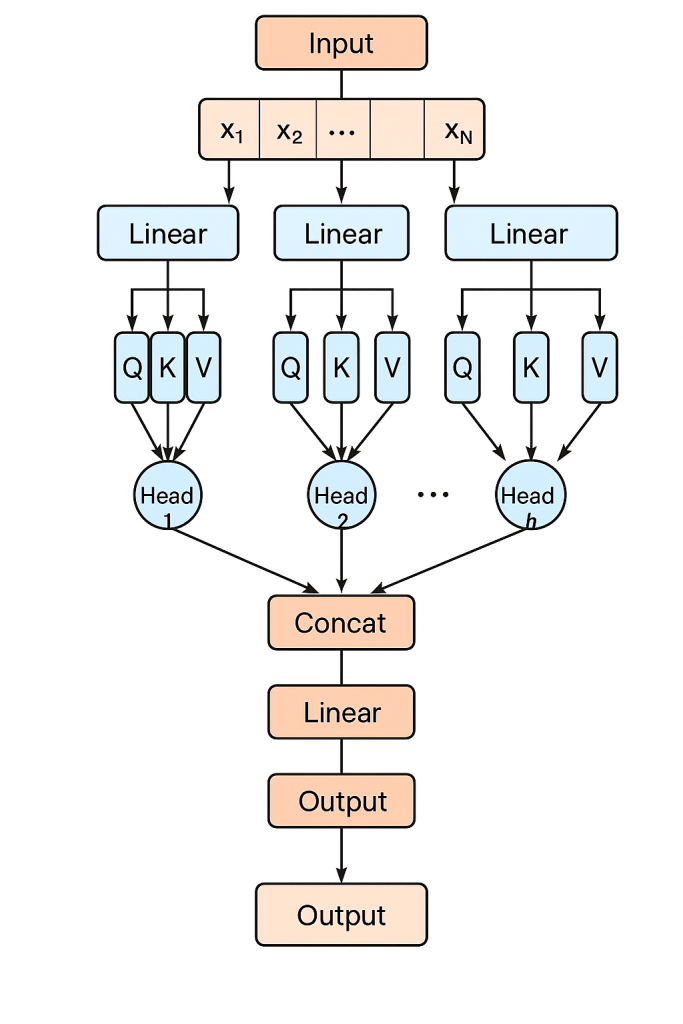
Multi-Head Attention
In practice, Transformers use multi-head attention. Instead of a single Q/K/V set, they use multiple heads, each learning different relationships between tokens. The model concatenates the outputs from these heads and projects them back into its embedding space. This allows the model to capture multiple types of relationships simultaneously, enhancing its ability to understand complex language patterns.
Conclusion
The self-attention mechanism is the reason LLMs understand nuanced relationships across a sequence. By learning how much each token should pay attention to every other token, it enables context-aware, high-performance NLP models. If you’re building or fine-tuning LLMs, understanding and experimenting with self-attention is a must. With the code and concepts above, you can now implement it from scratch and adapt it to your needs.
Discover more from CPI Consulting
Subscribe to get the latest posts sent to your email.