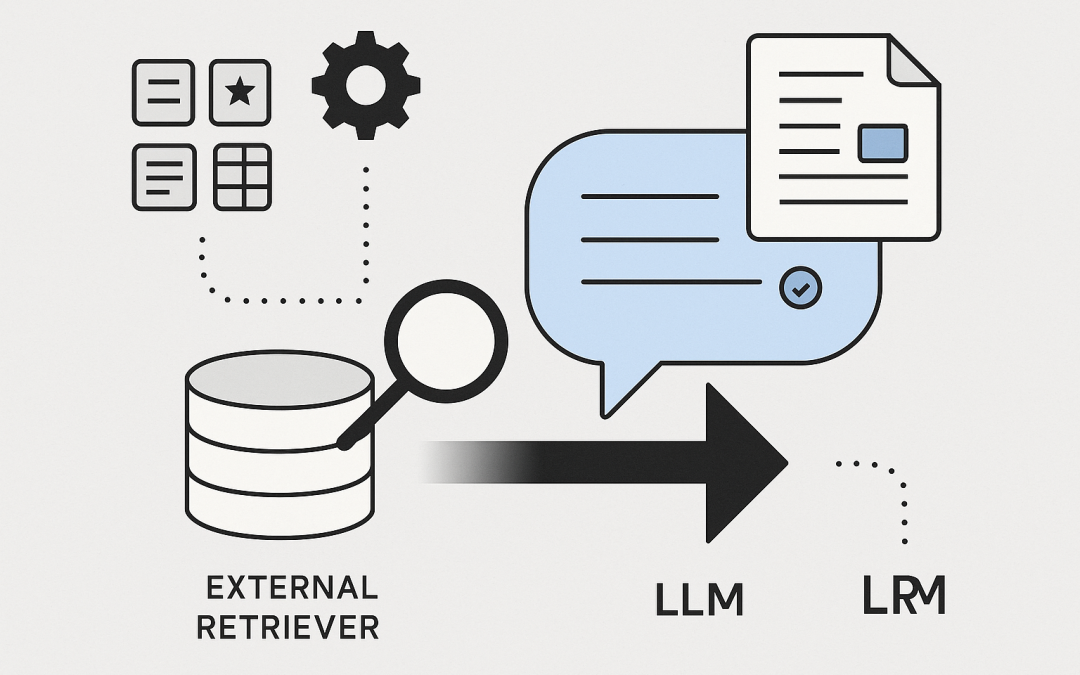
In this blog post Architecture of RAG Building Reliable Retrieval Augmented AI we will unpack how Retrieval Augmented Generation works, what to build first, and how to run it reliably in production.
Retrieval Augmented Generation (RAG) combines a large language model (LLM) with your own knowledge to produce grounded, current, and auditable answers. Instead of relying on a model’s memory, RAG pulls the right facts at query time and asks the model to write with them. The result: fewer hallucinations, better explainability, and control over data access.
This post starts with a clear overview, then dives into the technology and architecture. We’ll finish with a small, end‑to‑end Python example and a practical checklist you can use on day one.
What is RAG and why it matters
RAG is a pattern where an LLM is augmented with an external retrieval system. When a user asks a question, the system searches your content (wikis, PDFs, tickets, databases), retrieves the most relevant snippets, and feeds them into the model’s prompt. The LLM then answers using that context and cites sources.
Why it matters: you control the knowledge, you can update it without retraining, and you can audit what informed each answer. This makes RAG a strong fit for support automation, internal assistants, document Q&A, and regulated environments.
The technology behind RAG
Three technologies power RAG:
- LLMs generate text and follow instructions. They are excellent writers but can invent facts when uncertain. RAG reduces that risk by grounding the model with retrieved context.
- Embeddings turn text into high-dimensional vectors so we can measure semantic similarity. Sentences with similar meaning have similar vectors.
- Vector search finds the closest vectors to a query embedding quickly, even across millions of chunks. Stores range from FAISS (in-process) to managed services like Pinecone, Weaviate, Qdrant, or Postgres with pgvector.
A thin orchestration layer ties these together: transforming the query, running retrieval, optionally re-ranking results, constructing the prompt, calling the LLM, and capturing telemetry.
Core components of a RAG architecture
1) Ingestion and preprocessing
Good answers start with good content. Ingest from files, web, knowledge bases, or databases through connectors. Normalize text, remove boilerplate, preserve structure (titles, headings), and attach metadata (source, author, date, permissions).
- Chunking: Split documents into chunks that match the LLM’s memory window and your retrieval needs. Common sizes are 300–1,000 tokens with overlaps of 10–20% to keep context intact.
- PII and compliance: Redact or tag sensitive fields at ingestion. Keep an auditable lineage: document version, chunk ID, and hash.
2) Embeddings and vector store
Choose an embedding model suitable for your language and domain (e.g., E5, Instructor, or commercial APIs). Store vectors and metadata in a vector database. Keep raw text in object storage if you need to re-embed or re-chunk later.
- Dimensionality: Higher dimensions can capture nuance but increase storage and latency. 384–1,536 dims are common.
- Index type: For production, prefer approximate nearest neighbor (ANN) indexes (HNSW, IVF) to keep latency low at scale.
3) Retrieval pipeline
At query time, transform and search:
- Query understanding: Expand acronyms, add synonyms, or rewrite to optimize retrieval. Lightweight rules or an LLM can help.
- Hybrid search: Combine vector and keyword signals to balance semantics and exact matches. Reciprocal rank fusion (RRF) is practical and effective.
- Filters: Use metadata filters (date range, product, permissions) to enforce relevance and security.
- Re-ranking: Use a cross-encoder or reranker to reorder the top N results for better precision before generation.
4) Generation and prompting
Construct a prompt that instructs the LLM to use only provided context, cite sources, and be concise. Limit context length to avoid diluting relevance. Consider structured outputs (JSON) when downstream systems will parse results.
5) Guardrails, privacy, and governance
- Moderation: Screen inputs and outputs for policy violations.
- Access control: Apply row- or document-level permissions both at retrieval time and in cached results.
- Data residency and encryption: Encrypt at rest and in transit. Keep clear boundaries between tenant data.
6) Caching and performance
- Embedding cache: Avoid recomputing embeddings for unchanged text.
- Query result cache: Cache retrieval results for frequent queries with short TTLs.
- Prompt and response cache: Cache full LLM responses when appropriate to cut costs and latency.
7) Observability and evaluation
- Telemetry: Log query, retrieved chunks, chosen prompt, model response, and latencies with IDs for traceability.
- Quality: Measure precision@k, hit rate, answer faithfulness, and citation correctness. Use human review and synthetic datasets to iterate.
8) Deployment and scaling
- Throughput: Scale embeddings and retrieval horizontally; use batch operations.
- Latency budgets: Aim for 300–900 ms retrieval and keep total P95 under your UX target (often 2–4 seconds).
- Cost: Monitor token usage, index memory, and reranker compute. Right-size chunking to reduce waste.
Reference patterns you can adopt
Baseline single pass RAG
The simplest pipeline: embed query, retrieve top-k, optional rerank, build prompt, generate answer with citations. Great for FAQs, policy docs, and knowledge bases.
Multi-hop and graph RAG
For complex questions requiring multiple sources or relationships, chain retrieval steps or use a lightweight knowledge graph. The model can ask for a follow-up retrieval, summarize, then consolidate.
Agentic RAG with tools
Let the model decide when to search, when to read a table, or when to call an internal API. Add tool-use functions with guardrails and strict schemas to keep actions safe and auditable.
Minimal implementation example in Python
This example indexes local documents with FAISS, retrieves top matches, and calls an LLM. Swap components to match your stack.
# pip install sentence-transformers faiss-cpu openai tiktoken
import os
import glob
import time
from typing import List, Dict
import faiss
import numpy as np
from sentence_transformers import SentenceTransformer, CrossEncoder
from openai import OpenAI
# 1) Load and chunk documents
def load_texts(path_pattern: str) -> List[Dict]:
docs = []
for fp in glob.glob(path_pattern):
with open(fp, 'r', encoding='utf-8', errors='ignore') as f:
text = f.read()
docs.append({"id": fp, "text": text})
return docs
# Simple recursive chunking
def chunk(text: str, max_tokens: int = 500, overlap: int = 50) -> List[str]:
words = text.split()
chunks = []
i = 0
while i < len(words):
chunk_words = words[i : i + max_tokens]
chunks.append(" ".join(chunk_words))
i += max_tokens - overlap
return chunks
# 2) Build vector index
emb_model = SentenceTransformer("intfloat/e5-base-v2") # swap to your preference
raw_docs = load_texts("./docs/**/*.txt")
chunks, metadatas = [], []
for d in raw_docs:
for i, c in enumerate(chunk(d["text"])):
chunks.append(c)
metadatas.append({"doc_id": d["id"], "chunk_id": i})
embs = emb_model.encode(["query: " + c for c in chunks], normalize_embeddings=True)
embs = np.array(embs).astype('float32')
index = faiss.IndexFlatIP(embs.shape[1]) # cosine with normalized vectors
index.add(embs)
# Optional: cross-encoder for reranking
reranker = CrossEncoder("cross-encoder/ms-marco-MiniLM-L-6-v2")
# 3) Retrieval function
def retrieve(query: str, k: int = 8, rerank_k: int = 20) -> List[int]:
q_emb = emb_model.encode(["query: " + query], normalize_embeddings=True).astype('float32')
scores, idxs = index.search(q_emb, rerank_k)
candidates = [(int(i), float(s)) for i, s in zip(idxs[0], scores[0])]
# Rerank with cross-encoder for precision
pairs = [[query, chunks[i]] for i, _ in candidates]
ce_scores = reranker.predict(pairs)
ranked = sorted(zip([i for i, _ in candidates], ce_scores), key=lambda x: x[1], reverse=True)
return [i for i, _ in ranked[:k]]
# 4) Prompt and generation
client = OpenAI(api_key=os.getenv("OPENAI_API_KEY")) # or your provider
SYSTEM_PROMPT = (
"You are a helpful assistant. Answer using ONLY the provided context. "
"If the answer isn't in the context, say you don't know. Cite sources as [doc_id#chunk_id]."
)
def answer(query: str) -> str:
top_idxs = retrieve(query)
ctx = []
for i in top_idxs:
md = metadatas[i]
ctx.append(f"[ {md['doc_id']}#{md['chunk_id']} ]\n{chunks[i]}")
context = "\n\n".join(ctx)
prompt = (
f"Context:\n{context}\n\n"
f"Question: {query}\n"
f"Answer:"
)
resp = client.chat.completions.create(
model="gpt-4o-mini", # choose your model
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": prompt},
],
temperature=0.2,
)
return resp.choices[0].message.content
if __name__ == "__main__":
q = "What is our refund policy for annual plans?"
t0 = time.time()
print(answer(q))
print(f"\nLatency: {time.time() - t0:.2f}s")
This is intentionally minimal. In production, add streaming, retries, timeouts, permission filters, request/response logging with IDs, and evaluation hooks.
Common pitfalls and how to avoid them
- Overlong chunks: Huge chunks dilute relevance and waste tokens. Start with 500–800 tokens with overlap, then tune.
- No reranking: ANN recall is good but not perfect. A lightweight cross-encoder reranker boosts answer quality noticeably.
- Missing metadata: Without source, author, date, and permissions, you cannot filter or audit. Capture this at ingestion.
- Prompt bloat: Too much context hurts. Keep top-k small (4–10) and concise.
- Static content: Re-embed when documents change. Maintain a versioned index with a background updater.
- Zero observability: Log retrieval hits and misses. Tie user feedback to queries and documents to improve recall and precision.
A practical checklist to get started
- Pick initial use cases where ground truth exists (FAQs, policies, SOPs).
- Ingest and chunk with metadata and access controls.
- Choose an embedding model and build a vector index (ANN).
- Implement retrieval with hybrid search and reranking.
- Design a grounded prompt with citations and clear style.
- Add guardrails: moderation, PII redaction, permission filters.
- Instrument everything: latencies, token counts, retrieval traces.
- Evaluate with precision@k, faithfulness, and human review.
- Introduce caching and autoscaling as traffic grows.
- Iterate: tune chunking, k, reranker, and prompt based on data.
Final thoughts
RAG is less about a single model and more about a well-tuned system. If you get the plumbing right—clean content, smart retrieval, crisp prompts, and strong observability—you’ll ship assistants that are accurate, fast, and trustworthy. Start simple, measure relentlessly, and evolve toward multi-hop or agentic patterns only when the use case demands it.